
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失
kafka主要使用了以下几个方式实现了超高的吞吐率
顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能
顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写
Kafka官方给出了测试数据(Raid-5,7200rpm):
顺序 I/O: 600MB/s
随机 I/O: 100KB/s
零拷贝
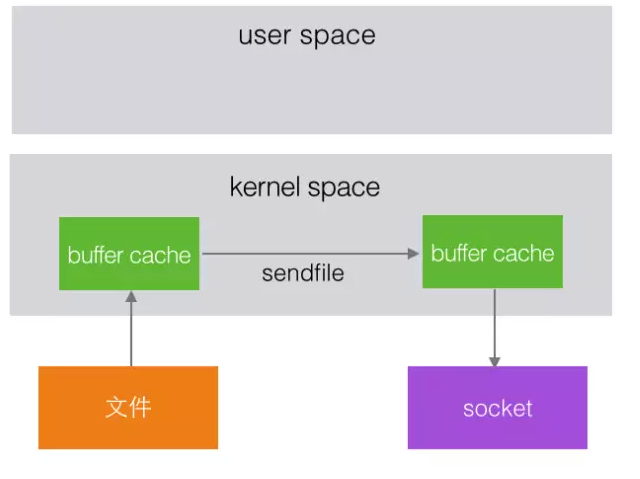
先简单了解下文件系统的操作流程,例如一个程序要把文件内容发送到网络
这个程序是工作在用户空间,文件和网络socket属于硬件资源,两者之间有一个内核空间
在操作系统内部,整个过程为:

在Linux kernel2.2 之后出现了一种叫做"零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”
系统上下文切换减少为2次,可以提升一倍的性能
文件分段
kafka的队列topic被分为了多个区partition,每个partition又分为多个段segment,所以一个队列中的消息实际上是保存在N多个片段文件中
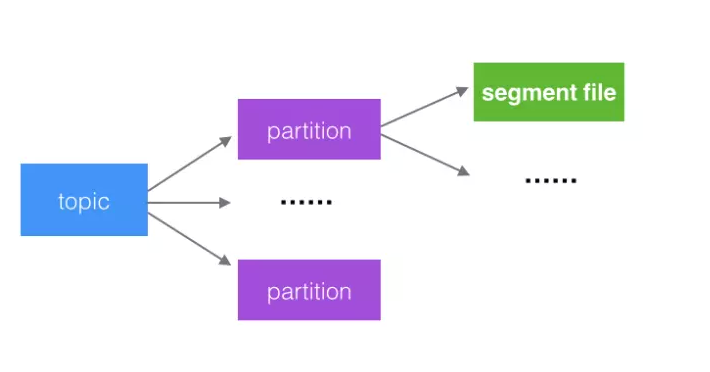
通过分段的方式,每次文件操作都是对一个小文件的操作,非常轻便,同时也增加了并行处理能力
批量发送
Kafka允许进行批量发送消息,先将消息缓存在内存中,然后一次请求批量发送出去
比如可以指定缓存的消息达到某个量的时候就发出去,或者缓存了固定的时间后就发送出去
如100条消息就发送,或者每5秒发送一次
这种策略将大大减少服务端的I/O次数
数据压缩
Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩
压缩的好处就是减少传输的数据量,减轻对网络传输的压力
Producer压缩之后,在Consumer需进行解压,虽然增加了CPU的工作,但在对大数据处理上,瓶颈在网络上而不是CPU,所以这个成本很值得
http://it.dataguru.cn/article-9855-1.html



相关推荐
由于它已经设计、优化并用于的服务器系统,每个流每秒产生超过 100 万个 I/O 密集型任务,其内部实现记录并发处理的实现高度优化,可以产生理想的吞吐量以最少的服务器数量,最大限度地提高资源利用率。入门/教程请...
【知识点 02】Kafka 与其它 MQ 相比,其最大的特点就是高吞吐率。Kafka 中消息存放的顺 序存放是实现高吞吐率的重要特征。请简述一下 Kafka 中消息的顺序存放特性。 【知识点 03】Kafka 中的 Segment 实际是一套文件...
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输 支持Kafka Server间的消息分区,及分布式...
1. 高吞吐率,kafka的高吞吐率是秒杀其他消息系统的,原因在批处理,压缩,多分区 等。 2. 高性能,MQ系统的性能瓶颈主要在于持久化和对消息消费的ack。kafka的持久化策略 采用文件系统以及page cache,消息直接从...
Kafka 是由 LinkedIn 开发的一个分布式的消息系统, 使用 Scala 编写, 它以可水平扩展和高吞吐率而被广泛使用。 目前越来越多的开源分布式处理系统如Cloudera、 Apache Storm、Spark 都支持与 Kafka 集成。
为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。若创建topic1和topic2两个topic,且分别有13...
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
是一款分布式消息发布和订阅的系统,具有高性能和高吞吐率。 消息的发布(publish)称作producer,消息的订阅(subscribe)称作consumer,中间的存储阵列称作broker。 多个broker协同合作,producer、consumer和...
kafka主要使用了以下几个方式实现了超高的吞吐率 顺序读写 kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能 顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以...
Kafka是由LinkedIn开发并开源的分布式消息系统,因其分布式及高吞吐率而被广泛使用,现已与ClouderaHadoop,ApacheStorm,ApacheSpark集成。本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的...
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。 同时支持离线数据处理和实时数据处理。 ...
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、ApacheStorm、Spark等都支持与...
kafka是一款分布式消息发布和订阅的系统,具有高性能和高吞吐率。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一个分布式的,可划分的,冗余备份的持久性的日志服务。它主要用于处理活跃的流式...
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、ApacheStorm、Spark等都支持与...
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。本课程主要是讲解...
Apache Kafka,作为一种分布式的消息系统,具有可水平扩展和高吞吐率而被广泛的使用。对于数据业务的基础支撑系统,除了能够满足高并发度和实时性以外,数据的质量即数据可靠性也是关键的一环。但是,由Kafka原生提供的...
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、ApacheStorm、Spark等都支持与...